
Da ich mit dem Thema Logdateien-Analyse zu tun hatte, habe ich das als Anlaß genommen, mir mal den ELK-Stack (Elasticsearch, Logstash, Kibana) anzusehen. Das ganze ist zwar zum zentralisierten Sammeln von Systemlogs gedacht, läßt sich aber auch zum Analysieren bestehender Logfiles nutzen. Als „Fingerübung“ diente die Fragestellung: Woher kommen denn die Leute, die regelmäßig von denyhosts in meinen Logdateien verewigt werden? ;-)
Logstash
Logstash ist sozusagen die „automatisierte Mistgabel“ für Logs. Logstash zapft Input-Quellen an (typischerweise Dateien, kann aber auch als Syslog-Daemon oder ähnliches dienen), bereitet sie in das gewünschte Format auf und schreibt das dann in ein oder mehrere Datensenken (beim klassischen ELK-Stack: Elasticsearch). In meinem Fall wollte ich die Logausgabe des denyhosts-Daemon sowie die Logausgaben der UFW im syslog parsen.
Da sich das denyhosts-Format als etwas tricky herausstellte, hier zunächst mal die Konfiguration für UFW. In meiner syslog-Konfiguration landen diese bereits in einer separaten Datei. Also konfiguriert man einen Input aus einer Datei und gibt dem ganzen einen Eingabe-Typ (selbst definiert, dient als Marker für die Filterregeln):
input {
file {
path => "/var/log/iptables.log"
type => "iptables"
}
}
Jede Zeile, die hier gelesen wird, dient als Ausgangsmaterial für einen Logeintrag. Das Format sieht bei UFW-Logs folgendermaßen aus:
Jul 6 03:22:08 localhost kernel: [1746862.282899] [UFW BLOCK] IN=eth0 OUT= MAC=de:ad:be:ef:12:34:56:78:00:00:00:00:00:00 SRC=1.2.3.4 DST=2.3.4.5 LEN=40 TOS=0x00 PREC=0x00 TTL=249 ID=4368 PROTO=TCP SPT=45983 DPT=3389 WINDOW=1024 RES=0x00 SYN URGP=0
Der String wird nun anhand einer Filterregel aufgebrochen:
filter {
if [type] == "iptables" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:timestamp} %{SYSLOGHOST:hostname}.*UFW BLOCK.*IN=%{NOTSPACE:dev_in}.*MAC=(?<mac>[0-9A-F]{2}(:[0-9a-fA-F]{2})*) SRC=%{IP:src_ip} DST=%{IP:dst_ip}.*SPT=%{NUMBER:src_port:int} DPT=%{NUMBER:dst_port:int}" }
}
}
}
grok ist die „eierlegende Wollmilchsau“ von logstash. Beim Entwerfen der Regeln ist die grok-Debuggingseite sehr hilfreich, hier kann man seine Regeln mit Testeingaben so lange ausprobieren, bis alles paßt.
logstash kennt als Datentypen zunächst nur String und Int; wenn man
nichts weiter unternimmt, wird ein Feld als String interpretiert. In
obigem Beispiel sieht man bei den Feldern src_port und dst_port,
daß diese explizit als Integer interpretiert werden sollen.
Für eine schöne Auswertung sollte aber der Zeitstempel auch als Zeit interpretiert werden! Dies erfolgt mit einem weiteren Filter:
date {
match => [ "timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
Damit wären die Daten zumidest rudimentär aufbereitet und in einzelne Felder aufgetrennt. Nun sollen diese in eine lokal laufende Elasticsearch-Instanz geschrieben werden:
output {
elasticsearch {
host => "127.0.0.1"
}
}
Geo-Informationen
Um die Analyse nach dem Ursprung zu ermöglichen, muß die zugehörige Geo-Information hinzugefügt werden. Hierfür bietet logstash den geoip-Filter, der anhand einer IP zugehörige Geo-Informationen ergänzt.
if [src_ip] {
geoip {
source => "src_ip"
target => "geoip"
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
}
mutate {
convert => [ "[geoip][coordinates]", "float" ]
}
}
Auf diese Filterregel bin ich auf dieser Seite gestoßen, der Autor versuchte, die Quellen von Apache-Zugriffen und Mails, die im Graylisting landen, auf einer Karte abzutragen.
Erneutes Einlesen von Logdateien
Für einen file-Input ist das Standardverhalten, am Ende der Datei zu beginnen, also auf neue Daten zu warten und die vorhandenen Daten zu ignorieren. Möchte man eine Datei vollständig einlesen, muß man dies explizit spezifizieren:
file {
path => "/var/log/iptables.log"
type => "iptables"
start_position => "beginning"
}
Dies sorgt dafür, daß die Datei komplett geparst wird – zumindest beim
ersten Mal. Anschließend merkt sich logstash die letzte Leseposition.
Gerade beim Einrichten von neuen Regeln möchte man manchmal aber das
komplette Neueinlesen erzwingen. Die letzte Leseposition wird
standardmäßig in den Dateien $HOME/.sincedb* gespeichert, löscht man
diese, wird die Datei nochmals komplett gelesen.
Ein eigener Filter
Bei den Logs von denyhosts wird es etwas trickreicher, diese sehen beispielsweise folgendermaßen aus:
2014-07-06 19:26:36,334 - denyhosts : INFO new denied hosts: ['1.2.3.4', '9.8.7.6', '2.4.6.8' ]
Das heißt, zu einer Zeile müssen mehrere Logeinträge erzeugt werden. Mein Ansatz: Zunächst die Zeile in Felder aufteilen, anschließend aus der Liste von IPs separate Einträge mit nur einer IP generieren. Zunächst also das Aufteilen:
if [type] == "denyhosts" {
grep {
match => { "message" => "new denied hosts" }
}
grok {
match => { "message" => "(?<timestamp>[0-9]{4}-[0-1][0-9]-[0-3][0-9] [0-2][0-9]:[0-5][0-9]:[0-5][0-9]).*new denied hosts: \[(?<src_ip>[^\]]*)\]" }
}
date {
match => [ "timestamp", "yyyy-MM-dd HH:mm:ss" ]
}
}
Der grep-Filter stammt aus dem logstash-contrib-Paket und ist an sich deprecated, aber oh my… ;-)
Nun enthält das Feld src_ip den Inhalt der eckigen Klammern oben. Der
Ruby-Befehl scan könnte hier den Job erledigen, allerdings gibt es
hierfür kein passendes Filter-Plugin. Glücklicherweise ist das Schreiben
eines solchen logstash-Plugins wirklich sehr einfach:
require "logstash/filters/base"
require "logstash/namespace"
class LogStash::Filters::Scan < LogStash::Filters::Base
config_name "scan"
milestone 1
config :field, :validate => :string, :required => true
config :regex, :validate => :string, :required => true
public
def register
# Nothing to do
end
public
def filter(event)
return unless filter?(event)
r=Regexp.new(@regex)
elements = event[@field].scan(r)
event[@field] = elements.shift
elements.each do |element|
new_event = event.clone
new_event[@field] = element
filter_matched(new_event)
yield new_event
end
end
endIn vielen anderen Beispielen für solche Filter sieht man, daß er
ursprüngliche Event mittels clone dupliziert und die neuen Events
mit filter_matched und yield zurückgeliefert werden; anschließend
wird der ursprüngliche Event mittels cancel verworfen. Dies hat bei mi
nicht funktioniert: Die neuen Events wurden von der weiteren Filterkette
nicht bearbeitet, d.h. das Hinzufügen der Geo-Informationen blieb aus.
Deshalb der obige Ansatz, bei dem er ursprüngliche Event erhalten
bleibt.
Der neue Filter wird nun folgendermaßen eingesetzt:
scan {
field => "src_ip"
regex => "\d*\.\d*\.\d*\.\d*"
}
Damit wären die Regeln komplett – die gesamte Datei kann hier heruntergeladen werden.
Kibana
Kibana selbst ist eine reine html-Seite, die sämtliche Darstellungs-Magie mittels Javascript und Zugriffen auf die Elasticsearch-Web-API erledigt. Hier kann man nun durch Hinzufügen einer map zum Standard-Panel die Daten nach Geo-Information auswerten:
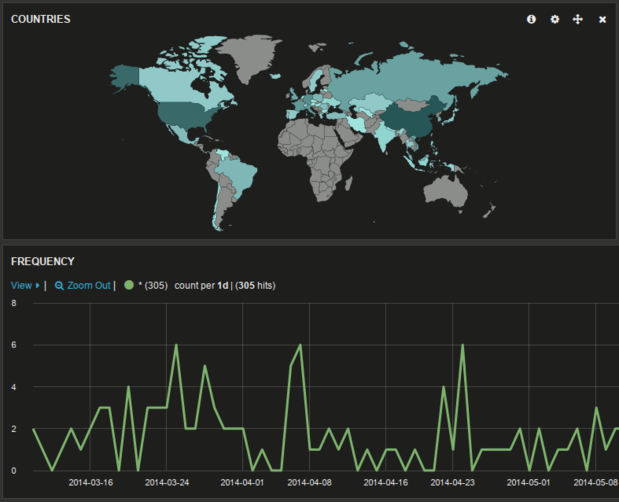
Fazit: Coole Tools, viel Spaß, grafischer Bling – und die Chinesen sind offenbar nicht an allem Schindluder im Netz schuld ;-)